Looking for experts to help build your AI products/features? Visit Jaseci Labs
With the ever rapid evolution of software being served on the backbone of the internet and sophisticated AI on the critical path of more products, the journey of creating software has become highly complex.
Further, there is a growing barrier to entry for smaller and less funded teams to create cutting-edge AI products. For this reason, we’ve created Jaseci, a new software system run-time stack and programming model that simplifies the creation of sophisticated, scale-out, AI (and other cloud) products.
The software ecosystem that comes with Jaseci allows a developer to simply articulate the design of a sophisticated AI product while abstracting away and automating the construction of production-grade, scalable, cloud software.
The key observation that inspired the development of Jaseci is that much of this complexity comes from the level of abstraction prevalent today for modern software. In particular, the programming languages used today originated with the view of a computer as a single machine. However, in reality a single ‘application’ is comprised of disparate software programs sprawling multiple compute environments with client software on phones or in browsers communicating with disperse server software running on a cloud. In this landscape, it has become prohibitively difficult for a single programmer to invent, build, deploy, and distribute cutting edge software.
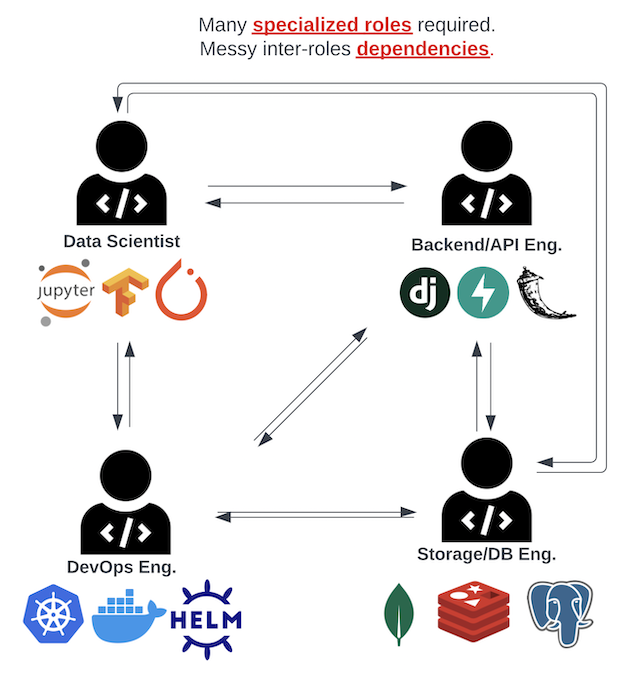
Here we see the typical set of ten siloed roles needed to create software in the current environment.
In this traditional model of software engineering, many challenges and complexity emerge. An example is the (quite typical) scenario of the first main server-side implementation of the application being a monoservice while DB, caching, and logging are microservices.
As the ML engineer introduces models of increasing size, the devops person alerts the team that the cloud instances, though designated as large, only have 8GB of ram. Meanwhile, new AI models being integrated exceed this limit. This event leads to a re-architecture of the main monoservice to be split out AI models into microservices and interfaces being designed or adopted leading to significant backend work/delays.
Our technical mission is to create a solution that would move all of this decisioning and work under the purview of the automated runtime system.
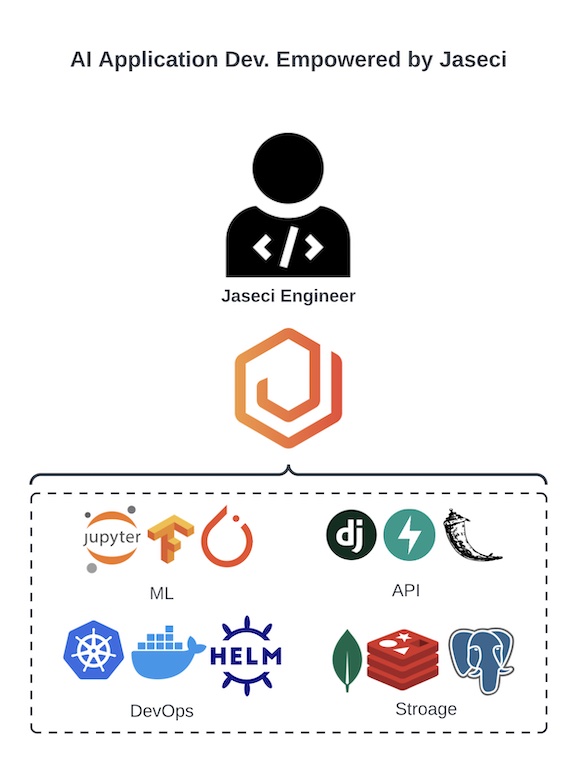
The mission of Jaseci is to accelerate and democratize the development and deployments of end-to-end scalable AI applications. To this end, Jaseci presents a novel set of higher level abstractions for programming sophisticated software in a micro-service/serverless AI and a full stack architecture and programming model that abstracts away and automates much of the complexity of building applications on a distributed compute substrate of potentially thousands of compute nodes. The design of Jaseci includes two major innovations.
Traditionally in computer science, the task of raising the level abstraction in a computational model has primarily been for the goal of increasing programmer productivity. This productivity comes from allowing engineers to function at the problem level while hiding the complexity of the underlying system. The Jac language introduces a set of new abstractions guided by these principles based on two key insights. First, Jac recognizes the emerging need for programmers to reason about and solve problems with graph representations of data. Second, Jac further supports the need for algorithmic modularity and encapsulation to change and prototype production software in place of prior running codebases. Based on these insights, we introduce two new sets of abstractions
Jaseci’s cloud-scale runtime engine presents a higher level ab- straction of the software stack. The diffuse runtime engine subsumes responsibility not only for the optimization of program code, but also for the orchestration, configuration, and optimization of constituent microservices and the full cloud compute stack. Duties such as container formation, microservice scaling, scheduling and optimization are automated by the runtime. Jaseci introduces the concept of container-linked libraries to complement traditional notions of statically and dynamically linked libraries. From the programmer’s perspective, they need not know whether a call to a library is fused with the running programming instance or a remote call to a microservice somewhere in a cluster. The decision of what should be a microservice and what should be statically in the programs’ object scope is made automatically and seamlessly by the Jaseci microservice orchestration engine.
Jaseci can accelerate and democratize the development and deployment of end-to-end scalable AI applications. The guiding principles of Jaseci OSE are:
To build trust and to empower developers to make de- cisions and drive directions, we are keen on making our decision process clearly documented and transparent to the community. Everyone has the clear understanding and knows how to participate and has their voice heard. By building a transparent community where people trust each other and the process, we will have motivated group of people that truly believe that their collaborative effort will create something beautiful and impactful together
The community thrives when people collaborate to make ideas stronger. Instead of having individuals with all of the decision-making power, we aim to build an environment where people brainstorm, collaborate, and work together on common projects. We strive to make our community inclusive and diverse. We believe inclusion and diversity will provide wider perspectives when we solve problems and lead to better solutions and outcomes. A collaborative and inclusive environment can also accelerate community growth by providing a welcoming environment to onboard new users and contributors. To stay on the cutting-edge of AI and systems, we also commit to incentivize innovation.